리눅스에서의 IPC Socket vs Network Socket
Unix Domain Socket은 리눅스 상에서 동작하는 클라이언트-서버 프로세스로 나뉜 소프트웨어에서 자주 사용된다. 예를 들어, Docker에서는 기본 설정으로 TCP Socket이 아닌 Unix Domain Socket으로 dockerd와 docker가 통신한다. 이 경우 외부에서 접속할 수 없다.
비슷하게 MySQL client도 host=”localhost”인 경우 Unix Socket을 사용한다.
이 글은 Unix Domain Socket이란 무엇이고, 그 사용 예와 특징에 대해 서술한다.
1. Socket의 종류
POSIX(리눅스/유닉스)에는 소켓이 2 종류가 존재한다.
여기서 Network Socket은 IP Socket, 즉 TCP, UDP 통신에 쓰이는 소켓이며, IPC Socket은 오늘의 주제인 Unix Domain Socket을 의미한다.
2. Unix Domain Socket
Unix Domain Socket, 줄여서 UDS는 IPC의 종류 중 하나로, TCP, UDP에 대응되는 API (SOCK_STREAM, SOCK_DGRAM)가 있기 때문에 소켓의 file descriptor를 할당 받는 구문만 변경하면 네트워크 소켓을 썼을 때와 같은 코드를 사용할 수 있게 된다.
1 |
|
자세한 UDS 코드에 대해선 간결한 설명은 이 블로그를 참고하고, 자세한 설명은 이 블로그를 참고하면 좋을 것 같다.
UDS를 사용할 경우 하부의 네트워크 프로토콜을 거치지 않고 OS 커널만을 통해서 통신이 이루어진다. 따라서 UDP를 사용한 코드더라도 UDS를 쓴다면 항상 순서가 보장되는 등 네트워크의 불확실성이 모두 제거된다.
참고로 IPC의 경우 UDS보다 더 빠른 방법들이 많다 - 가장 빠른 것은 shared memory 방법이라고 한다 [IPC 성능 측정에 대한 글]. 해당 링크를 따라가면 알겠지만 IPC 방법 중에는 메모리 복사를 줄일 수 있는 방법이 많은 데 비해 UDS가 가장 많은 메모리 복사를 하는 것을 알 수 있다.
UDS는 리눅스의 파일 권한을 따르므로, 통신에 대한 권한을 제어할 수 있다.
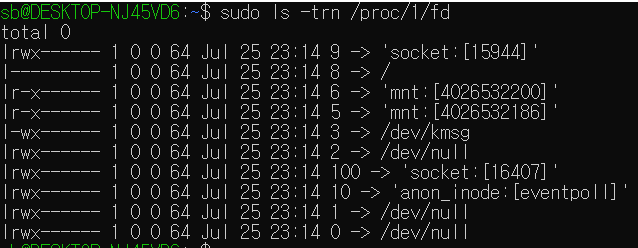
Linux는 소켓도 파일로 관리하는데, UDS는 파일 속성의 첫 글자가 srwxrwxrwx와 같이 s이다. Network 소켓도 소켓이기 때문에 파일이긴 하지만, UDS는 파일 이름이 있고, Network Socket은 파일 이름이 없어서(unnamed) 포트로 접근해야 한다. UDS 소켓 코드를 보면, UDS 소켓의 경로를 알고, 해당 파일에 대한 권한이 있으면 해당 소켓으로 통신을 수행할 수 있다. 따라서 해당 소켓 파일에 대한 접근 권한을 통해 통신 권한도 조절할 수 있다!
TODO
Socket 프로그래밍 해보고 실제 코드 차이에 대해 더 뜯어보기
loopback IP에서의 overhead 비교해보기
다른 IPC 메커니즘과 성능 비교해보기